library(tidyverse)Cuarto paso. Responder preguntas con datos
Objetivo
Hasta ahora cargamos la base, miramos su estructura y aprendimos a manipularla. Ahora vamos a construir algunas variables nuevas, producir tablas descriptivas y hacer algunos gráficos simples para responder preguntas de investigación.
La pregunta general que nos va a orientar es:
¿Una actitud favorable hacia la inteligencia artificial implica confianza en sus capacidades concretas?
Cargamos paquetes y datos
encuesta_ia <- read_csv(
"https://raw.githubusercontent.com/gastonbecerra/primeros-pasos-r/refs/heads/main/data/encuesta_ia_subset.csv",
show_col_types = FALSE
)Pregunta 1: ¿qué tan favorable es la actitud general hacia la IA?
En la base tenemos varias variables que miden actitudes hacia la IA. De hecho, las podemos seleccionar por su nombre para chusmear solo ese pedazo de nuestra tabla.
encuesta_ia %>%
select(starts_with("actitud_"))# A tibble: 139 × 4
actitud_positiva actitud_trabajo_estudio actitud_vida_cotidiana
<dbl> <dbl> <dbl>
1 3 3 4
2 4 5 5
3 3 4 4
4 3 1 1
5 3 4 4
6 4 4 5
7 1 4 4
8 5 5 5
9 5 5 5
10 4 4 4
# ℹ 129 more rows
# ℹ 1 more variable: actitud_aprender_ia <dbl>Cada columna mide un aspecto distinto: una actitud general positiva, la valoración de la IA en el trabajo o el estudio, en la vida cotidiana, y la disposición a aprender más sobre IA.
Pero nuestra pregunta no refiere a cada ítem por separado, sino a una medida general de actitud. Para eso vamos a construir un indicador, es decir, un valor que sintetice la actitud de cada persona encuestada.
Particularmente, para esta escala de actitudes podemos usar el promedio de los 4 items:
encuesta_ia <- encuesta_ia %>%
mutate(
actitud_ia = (
actitud_positiva +
actitud_trabajo_estudio +
actitud_vida_cotidiana +
actitud_aprender_ia
) / 4
)Como usamos <-, el resultado queda guardado en memoria dentro del objeto encuesta_ia. Esto es importante porque vamos a usar esta nueva variable en las preguntas siguientes.
Ahora podemos calcular un resumen de la actitud general hacia la IA. Como eventualmente nos interesa sólo un número, luego de calcularlo vamos a tomar ese número sólo y guardarlo en una variable (pull()), perdiendo la estructura de tabla.
actitud_global_media <- encuesta_ia %>%
summarize(actitud_global_media = mean(actitud_ia)) %>%
pull(actitud_global_media)
actitud_global_media[1] 3.773381Mejor lo redondeamos….
actitud_global_media <- round(actitud_global_media, 2)
actitud_global_media [1] 3.77Grafiquemos! En este caso usamos geom_histogram() porque queremos observar la distribución de las actitudes globales de cada encuestado hacia la IA (actitud_ia).
ggplot(encuesta_ia, aes(x = actitud_ia)) +
geom_histogram(binwidth = 1) + # dibujamos 1 barra por cada punto de la encuesta 1-5
labs( # Agregamos títulos y nombres de ejes
title = "Distribución de la actitud general hacia la IA",
x = "Actitud general hacia la IA",
y = "Cantidad de casos"
) + theme_minimal() # sin fondo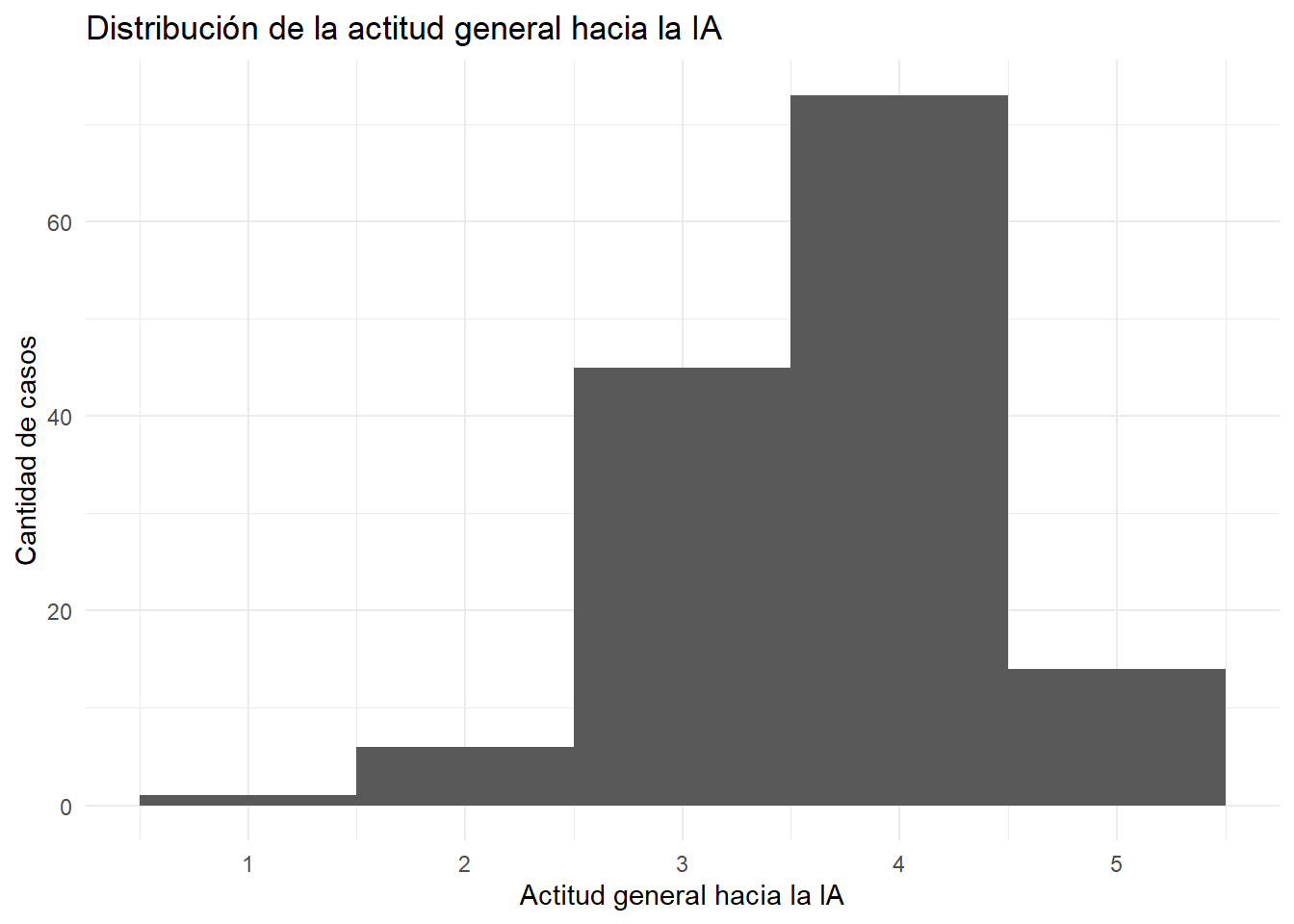
Como la escala va de 1 a 5, valores por encima de 3 indican una actitud relativamente favorable hacia la IA. Por lo que podemos ver, en nuestra base la mayoría de las personas encuestadas muestra una actitud favorable hacia la IA.
Pregunta 2: ¿la actitud cambia según la frecuencia de uso?
Ahora que guardamos la actitud de cada encuestado en actitud_ia, podemos usarla para comparar grupos.
La pregunta es:
¿La actitud general hacia la IA cambia según la frecuencia de uso?
La frecuencia de uso tiene 4 categorías posibles. Podemos calcular el promedio de actitudes en esos 4 grupos. Guardemos esto así en un objeto para que sea más fácil graficarlo. Además, vamos a hacer un paso más para que nuestros gráficos se vean mejor: vamos a indicarle que nuestras categorías tienen un orden y vamos a corregir sus mayúsculas y acentos, para que quede así: Nunca -> Esporádico -> Ocasional -> Frecuente. Para ello vamos a convertir nuestra variable en un factor.
actitud_por_uso <- encuesta_ia %>% #dentro de nuestra base de datos
mutate( #vamos a transformar
frecuencia_uso_ia = factor( # convertirmos en un factor y cambiamos etiquetas
frecuencia_uso_ia, # tomamos la variable que existe en la base
levels = c("nunca", "esporadicamente", "ocasional", "frecuente"), # le decimos que las cateorías de la variable original tienen este orden de jerarquía: “nunca” es menos que “esporádicamente”, y “esporádicamente” es menos que “ocasional”, etc.
labels = c("Nunca", "Esporádico", "Ocasional", "Frecuente") ) ) %>% # cambiamos las etiquetas para ser aptas para publicar, con mayúsculas y tildes
group_by(frecuencia_uso_ia) %>% # ahora hacemos los cálculos por cada grupo
summarise(
n = n(),
actitud_media = round(mean(actitud_ia), 2),
.groups = "drop" )
actitud_por_uso# A tibble: 4 × 3
frecuencia_uso_ia n actitud_media
<fct> <int> <dbl>
1 Nunca 6 2.67
2 Esporádico 25 3.42
3 Ocasional 54 3.8
4 Frecuente 54 4.04Ahora hacemos un gráfico con ggplot. Acá usamos puntos, y no barras, porque estamos comparando promedios en una escala que va de 1 a 5. Las barras suelen funcionar mejor cuando la escala empieza en 0, como conteos o porcentajes.
ggplot( actitud_por_uso, #graficamos nuestra nueva creación
aes(x = frecuencia_uso_ia, y = actitud_media)) + #le decimos qué va en x y qué en y
geom_point(size = 3) + # vamos a darle un tamaño 3 a los puntos del gráfico
geom_text(aes(label = actitud_media), vjust = -0.8) + #queremos que el gráfico tenga las etiquetas de actitud_media y le decimos en qué lugar del gráfico las ponemos
scale_y_continuous( limits = c(1, 5), breaks = 1:5 ) + #vamos a detallar la escala del eje y
labs( title = "Actitud hacia la IA según frecuencia de uso",
x = "Frecuencia de uso de IA",
y = "Actitud media" ) +
theme_minimal()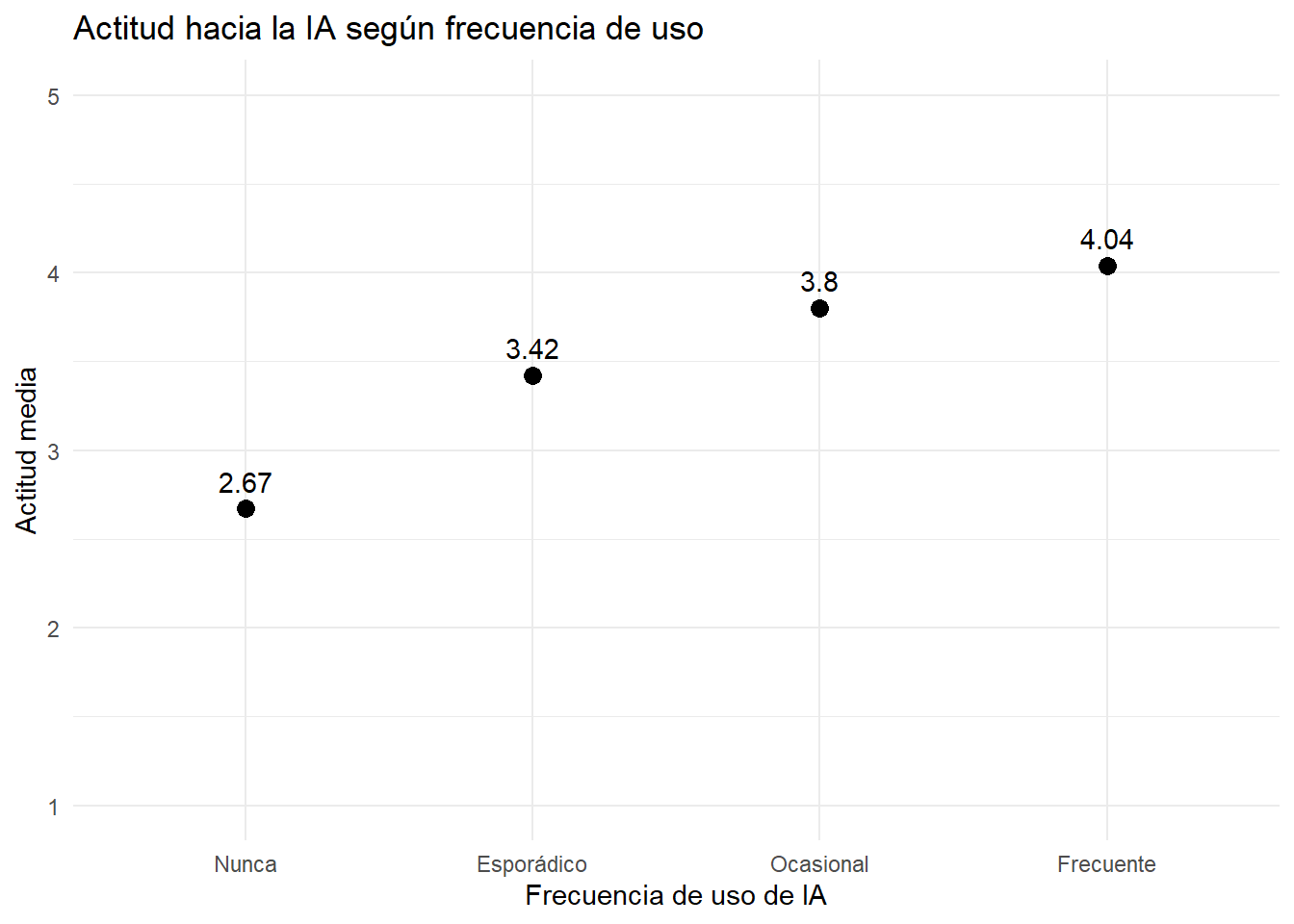
El gráfico muestra la comparación entre grupos: a mayor frecuencia de uso, mayor actitud promedio hacia la IA. El promedio más bajo aparece entre quienes dicen no usar IA, mientras que el más alto aparece entre quienes la usan de manera frecuente. De todos modos, conviene mirar también la cantidad de casos. La categoría nunca tiene pocos casos, por lo que ese valor debe leerse con cuidado.
Pregunta 3: ¿en qué capacidades de la IA se confía más y menos?
Además de las actitudes generales, la base tiene variables sobre creencias en capacidades específicas de la IA, utilizando la misma escala de respuesta 1-5. Eso nos permite compararlas y formular nuestra pregunta:
¿En qué capacidades de la IA se confía más y en cuáles se confía menos?
Para responderla, necesitamos calcular el promedio de cada creencia… y son 6 creencias disintas: que la IA es capaz de enseñar, de dar respuestas corectas, de dar respuestas justas, de ofrecer compañía, y brindar apoyo psicológico. Entonces, si quisiéramos calcular cada promedio debería hacerlo sobre cada columna distinta…
Aquí es cuando un nuevo formato de tabla, un nuevo modo de ordenar la información, puede sernos útil. ¿Que tal si hacemos una tabla donde haya una columna que indique cuál es la creencia y otra columna que tenga el valor de la respuesta? Es decir, queremos hacer esto:
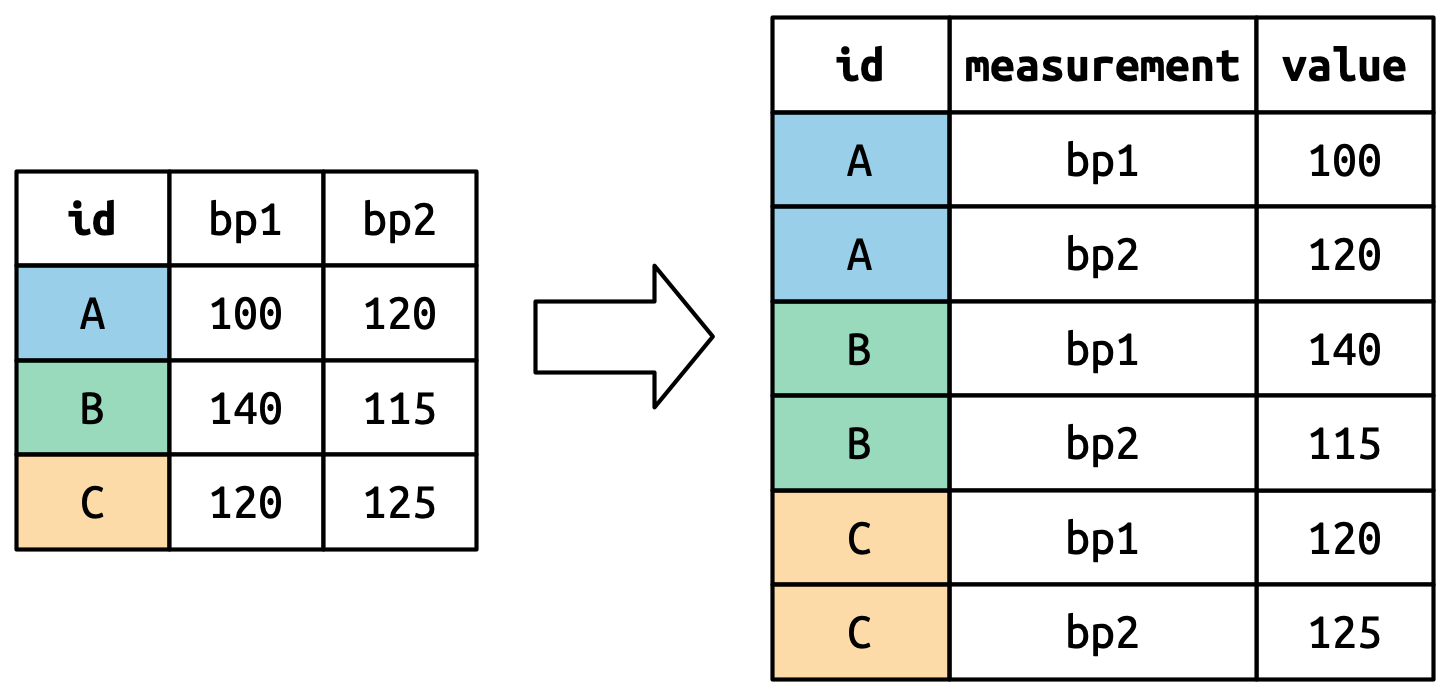
A este cambio se lo suele llamar pasar de formato ancho a formato largo. En el formato ancho, las creencias están en los nombres de las columnas. Pero en el formato largo, las creencias pasan a estar dentro de la misma variable. Eso nos permite agrupar por creencia y calcular un promedio para cada una.
Para hacer ese cambio vamos a hacer dos cosas: primero vamos a quedarnos con las variables que remiten a creencias (de hecho, las vamos a seleccionar por su nombre), y luego usamos pivot_longer() para transponerla y dividir sus valores en 2 columnas (creencia/valor):
creencias_largo <- encuesta_ia %>%
select(id_caso, starts_with("creencia_")) %>%
pivot_longer(
cols = starts_with("creencia_"),
names_to = "creencia",
values_to = "valor"
)Guardamos el resultado en un nuevo objeto llamado creencias_largo. No reemplazamos encuesta_ia, porque la base original nos sigue sirviendo para otras preguntas.
Veamos cómo quedó:
glimpse(creencias_largo)Rows: 834
Columns: 3
$ id_caso <dbl> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4…
$ creencia <chr> "creencia_decisiones_justas", "creencia_respuestas_certeras",…
$ valor <dbl> 1, 2, 1, 3, 4, 4, 3, 2, 2, 2, 3, 5, 3, 3, 1, 1, 3, 4, 2, 3, 2…Ahora cada fila representa una respuesta de una persona a una creencia específica. Notemos que ahora tenemos 6 veces más filas que antes!
nrow(encuesta_ia)[1] 139nrow(creencias_largo)[1] 834Con esta estructura, la comparación es mucho más directa, ya que podemos agrupar por creencias y operar sobre valores.
creencias_resumen <- creencias_largo %>%
group_by(creencia) %>%
summarise(
media_creencia = round(mean(valor), 2),
.groups = "drop"
) %>%
arrange(desc(media_creencia))
creencias_resumen# A tibble: 6 × 2
creencia media_creencia
<chr> <dbl>
1 creencia_ensenanza 3.5
2 creencia_investigacion 2.95
3 creencia_respuestas_certeras 2.53
4 creencia_decisiones_justas 2.4
5 creencia_compania 2.27
6 creencia_orientacion_psicologica 1.82Ahora hacemos un gráfico de puntos.
ggplot(creencias_resumen, aes(x = reorder(creencia, media_creencia), y = media_creencia)) +
geom_point(size = 3) +
geom_text(aes(label = media_creencia), hjust = -0.4) +
coord_flip() +
scale_y_continuous(
limits = c(1, 5),
breaks = 1:5
) +
labs(
title = "Creencias sobre capacidades específicas de la IA",
x = NULL,
y = "Promedio de acuerdo"
) +
theme_minimal()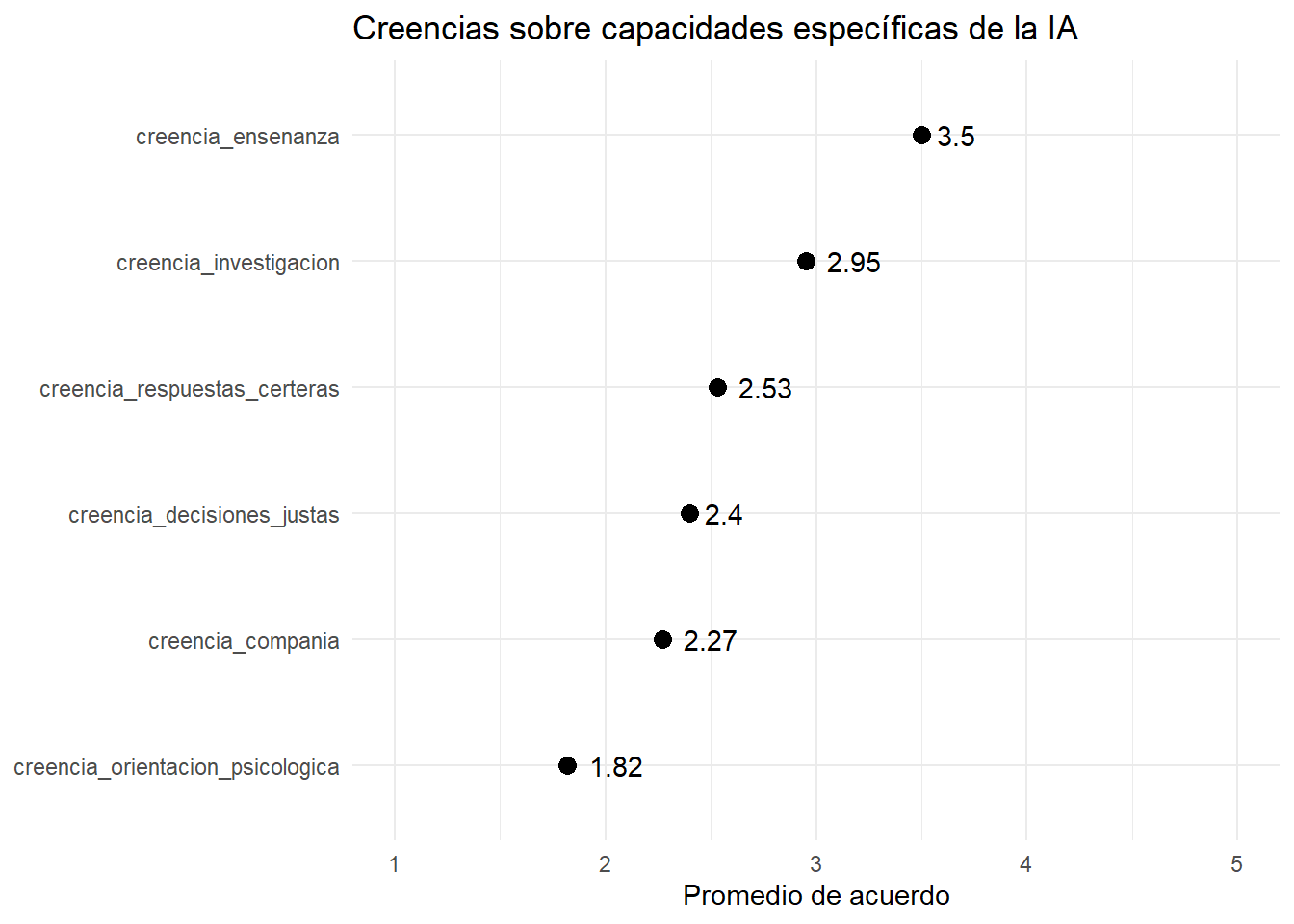
Este gráfico permite comparar las capacidades entre sí. La línea punteada marca el punto medio de la escala. Como podemos ver, la confianza no se distribuye de forma homogénea. Las capacidades vinculadas con conocimiento y aprendizaje aparecen mejor posicionadas, sobre el 3 o casi. En cambio, las capacidades afectivas o sensibles, como brindar compañía u ofrecer orientación psicológica, muestran niveles de acuerdo más bajos.
Pregunta 4: ¿la actitud general coincide con la confianza en capacidades específicas?
Ya vimos que las creencias sobre capacidades específicas de la IA no se distribuyen de manera homogénea.
Ahora podemos hacer una comparación más directa:
¿La actitud general hacia la IA está al mismo nivel que la confianza en sus capacidades específicas?
Para responderlo, vamos a usar el gráfico anterior, pero agregando una línea de referencia: la actitud general promedio hacia la IA que ya habíamos calculado en la primera pregunta (actitud_global_media).
ggplot(creencias_resumen, aes(x = media_creencia, y = reorder(creencia, media_creencia))) +
geom_point(size = 3) +
geom_vline(xintercept = actitud_global_media, linewidth = 2, linetype = "dashed", color = "red") +
geom_text(aes(label = media_creencia), hjust = -0.4) +
scale_x_continuous(
limits = c(1, 5),
breaks = 1:5
) +
labs(
title = "Creencias específicas y actitud general hacia la IA",
subtitle = paste("Línea punteada: actitud general promedio =", actitud_global_media),
x = "Promedio de acuerdo",
y = NULL
) +
theme_minimal()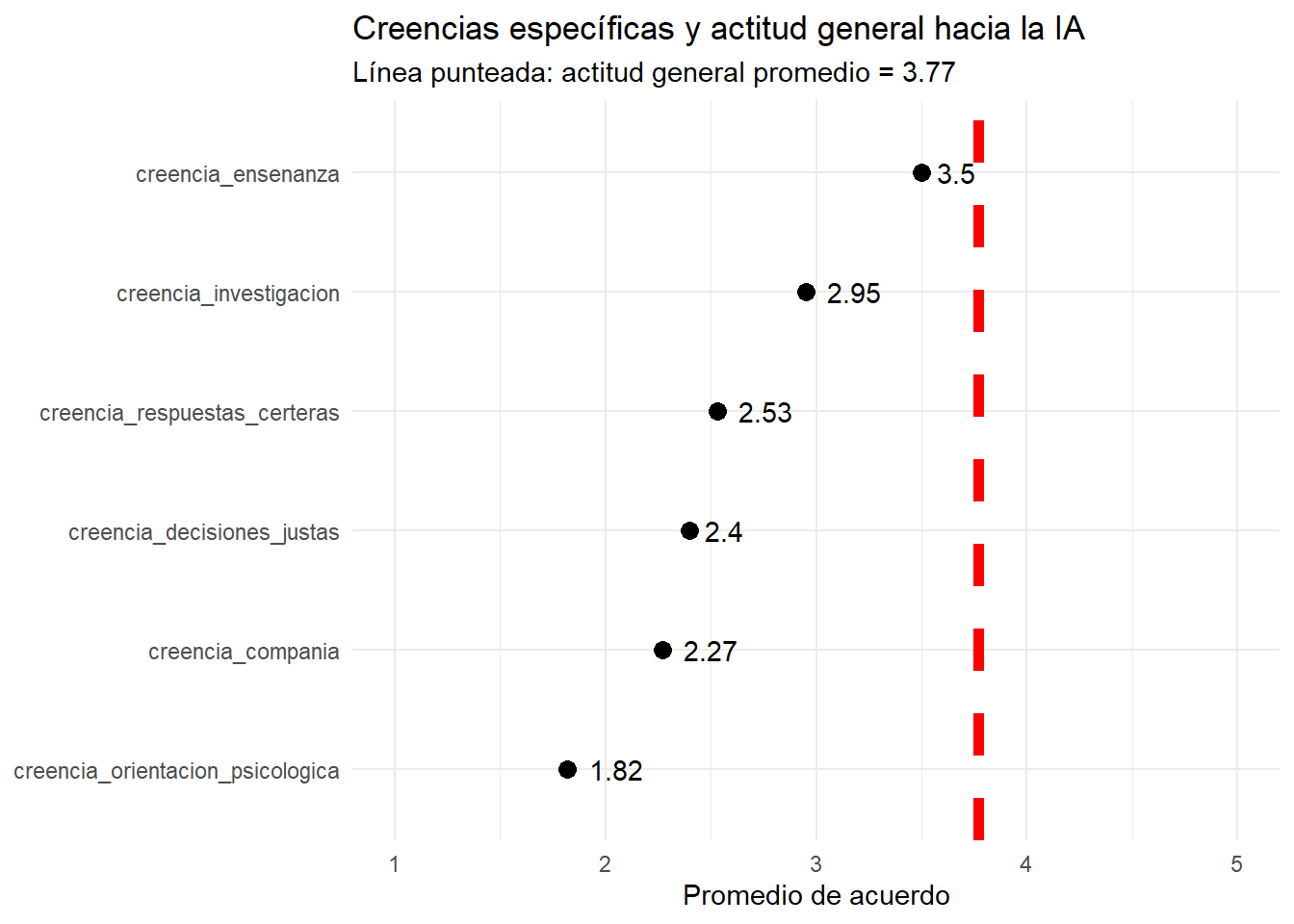
En este gráfico, cada punto representa el promedio de acuerdo con una capacidad específica de la IA. La línea punteada marca la actitud general promedio.
La lectura principal es que la actitud general hacia la IA queda por encima de todas las creencias específicas. Es decir: valorar positivamente la IA en términos generales no implica confiar del mismo modo en sus capacidades concretas. De hecho, pareciera que una actitud global puede esconder grandes diferencias: la confianza aparece más alta en tareas vinculadas con conocimiento y aprendizaje, y en cambio, es más baja en capacidades afectivas o sensibles, como brindar compañía u ofrecer orientación psicológica.