library(tidyverse)Tercer paso. Ordenar, filtrar y transformar datos
Objetivo
En este tutorial vamos a empezar a manipular nuestra tabla. Ya vimos cómo cargarla, mirar sus dimensiones, inspeccionar sus primeras filas y hacer conteos básicos. Ahora vamos a avanzar un paso más: ordenar resultados, calcular porcentajes, seleccionar columnas, filtrar casos y crear nuevas variables.
La idea no es aprender funciones de memoria, sino empezar a traducir preguntas simples en operaciones sobre una tabla.
Cargamos paquetes y datos
Como en el paso anterior, primero cargamos los paquetes que vamos a usar.
Y volvemos a cargar la base.
encuesta_ia <- read_csv(
"https://raw.githubusercontent.com/gastonbecerra/primeros-pasos-r/refs/heads/main/data/encuesta_ia_subset.csv",
show_col_types = FALSE
)¿Cómo encadenamos operaciones?
En el paso anterior usamos funciones sueltas. Por ejemplo, usamos count() para contar cuántos casos había en cada categoría:
count(encuesta_ia, area_trabajo_grupo)A medida que el análisis avanza, muchas veces necesitamos hacer varias operaciones seguidas: contar, ordenar, calcular porcentajes, filtrar, seleccionar columnas, etc.
Para eso vamos a usar el operador %>%, que se llama pipe.
El pipe nos permite escribir el código de izquierda a derecha, empezando por la tabla y agregando operaciones una detrás de otra.
La estructura general es:
tabla %>%
funcion_1() %>%
funcion_2() %>%
funcion_3()Podemos leerlo como:
tomá esta tabla, después aplicá esta función, después aplicá esta otra.
Por ejemplo:
encuesta_ia %>%
count(area_trabajo_grupo)# A tibble: 3 × 2
area_trabajo_grupo n
<chr> <int>
1 Consultoría / servicios profesionales 39
2 Educación 50
3 Salud y servicios sociales 50Este código hace lo mismo que:
count(encuesta_ia, area_trabajo_grupo)# A tibble: 3 × 2
area_trabajo_grupo n
<chr> <int>
1 Consultoría / servicios profesionales 39
2 Educación 50
3 Salud y servicios sociales 50Pero la escritura con pipe tiene una ventaja: nos permite seguir agregando pasos sin reescribir toda la operación. Por ejemplo, después de contar las áreas de trabajo, podemos ordenar el resultado con arrange():
encuesta_ia %>%
count(area_trabajo_grupo) %>%
arrange(area_trabajo_grupo) # ordenamos alfabeticamente por area# A tibble: 3 × 2
area_trabajo_grupo n
<chr> <int>
1 Consultoría / servicios profesionales 39
2 Educación 50
3 Salud y servicios sociales 50Leído paso a paso:
- tomamos la tabla
encuesta_ia; - contamos los casos por área de trabajo;
- ordenamos el resultado.
¿Cómo hacemos transformaciones?
Hasta ahora venimos contamos casos y ordenamos resultados. Pero para responder preguntas más interesantes vamos a tener que transformar nuestra tabla, agregando columnas nuevas que resulten de alguna operación (generalmente, otras columnas de la fila).
Para eso usamos mutate().
La idea general es:
tabla %>%
mutate(
nueva_columna = operacion
)Por ejemplo, podemos crear una variable que indique si la persona tiene 45 años o más. Al final de este código usamos select() solo para mostrar algunas columnas y que la salida sea más fácil de leer.
encuesta_ia %>%
mutate(
mayor_45 = edad >= 45
) %>%
select(id_caso, edad, grupo_edad, mayor_45) # vamos a quedarnos con solo unas columnas# A tibble: 139 × 4
id_caso edad grupo_edad mayor_45
<dbl> <dbl> <chr> <lgl>
1 1 45 45-59 TRUE
2 2 57 45-59 TRUE
3 3 45 45-59 TRUE
4 4 60 60+ TRUE
5 5 55 45-59 TRUE
6 6 30 30-44 FALSE
7 7 65 60+ TRUE
8 8 68 60+ TRUE
9 9 59 45-59 TRUE
10 10 19 18-29 FALSE
# ℹ 129 more rowsLa nueva columna mayor_45 toma dos valores:
TRUE: la condición se cumple;FALSE: la condición no se cumple.
Si queremos guardar esa nueva columna dentro de nuestra tabla, tenemos que volver a asignar el resultado al objeto encuesta_ia.
encuesta_ia <- encuesta_ia %>%
mutate(
mayor_45 = edad >= 45
)Ahora podemos contar la nueva variable:
encuesta_ia %>%
count(mayor_45)# A tibble: 2 × 2
mayor_45 n
<lgl> <int>
1 FALSE 69
2 TRUE 70Como resultado descubrimos que nuestros encuestados se dividen en dos grupos parejos: de nuestras 139 personas encuestadas, 70 tienen más de 45 años.
¿Cómo agrupamos datos?
Por ejemplo, si queremos saber la distribución de personas según su frecuencia de uso de IA, necesitamos agrupar la tabla por esa variable y contar cuántos casos hay en cada grupo.
Para eso podemos usar group_by() y summarise().
encuesta_ia %>%
group_by(frecuencia_uso_ia) %>%
summarise(n = n())# A tibble: 4 × 2
frecuencia_uso_ia n
<chr> <int>
1 esporadicamente 25
2 frecuente 54
3 nunca 6
4 ocasional 54Leído paso a paso:
- tomamos la tabla encuesta_ia;
- contamos los casos según frecuencia_uso_ia, lo que veremos como una columna;
- creamos una segunda columna de porcentajes (recuento de casos sobre total de casos por cien) para cada tipo de frecuencia de uso con ia.
La función n() cuenta la cantidad de filas dentro de cada grupo.
Esta operación es tan común que dplyr tiene una forma abreviada: count().
Si, además quisiéramos incluir los porcentajes, podríamos hacer:
encuesta_ia %>%
count(frecuencia_uso_ia) %>%
mutate(
porcentaje = n / sum(n) * 100
)# A tibble: 4 × 3
frecuencia_uso_ia n porcentaje
<chr> <int> <dbl>
1 esporadicamente 25 18.0
2 frecuente 54 38.8
3 nunca 6 4.32
4 ocasional 54 38.8 donde:
n / sum(n) * 100divide cada frecuencia por el total de casos y multiplicamos por 100.
¿Cómo miramos un grupo específico?
A veces lo que nos interesa no refiere a toda la base, sino a un grupo particular. Por ejemplo:
¿Cómo se distribuye la frecuencia de uso de IA entre quienes trabajan en educación?
Para responder eso, primero filtramos la base, trabajando solamente con las filas donde area_trabajo_grupo es igual a "Educación".
encuesta_ia %>%
filter(area_trabajo_grupo == "Educación") %>%
count(frecuencia_uso_ia)# A tibble: 4 × 2
frecuencia_uso_ia n
<chr> <int>
1 esporadicamente 7
2 frecuente 22
3 nunca 1
4 ocasional 20También podemos combinar condiciones:
encuesta_ia %>%
filter(
area_trabajo_grupo == "Educación",
frecuencia_uso_ia == "frecuente"
)# A tibble: 22 × 16
id_caso edad grupo_edad area_trabajo_grupo frecuencia_uso_ia
<dbl> <dbl> <chr> <chr> <chr>
1 2 57 45-59 Educación frecuente
2 4 60 60+ Educación frecuente
3 5 55 45-59 Educación frecuente
4 8 68 60+ Educación frecuente
5 9 59 45-59 Educación frecuente
6 11 45 45-59 Educación frecuente
7 13 43 30-44 Educación frecuente
8 17 39 30-44 Educación frecuente
9 18 61 60+ Educación frecuente
10 19 65 60+ Educación frecuente
# ℹ 12 more rows
# ℹ 11 more variables: actitud_positiva <dbl>, actitud_trabajo_estudio <dbl>,
# actitud_vida_cotidiana <dbl>, actitud_aprender_ia <dbl>,
# creencia_decisiones_justas <dbl>, creencia_respuestas_certeras <dbl>,
# creencia_orientacion_psicologica <dbl>, creencia_compania <dbl>,
# creencia_investigacion <dbl>, creencia_ensenanza <dbl>, mayor_45 <lgl>En filter(), la coma funciona como un y: conserva los casos que cumplen todas las condiciones.
También podemos usar condiciones numéricas. Por ejemplo, quedarnos con personas de 45 años o más:
encuesta_ia %>%
filter(edad >= 45) %>%
count(frecuencia_uso_ia) %>%
mutate(
porcentaje = round(n / sum(n) * 100, 1)
)# A tibble: 4 × 3
frecuencia_uso_ia n porcentaje
<chr> <int> <dbl>
1 esporadicamente 10 14.3
2 frecuente 29 41.4
3 nunca 4 5.7
4 ocasional 27 38.6Leído paso a paso:
- tomamos la tabla encuesta_ia;
- filtramos los casos que tienen 45 años o más;
- contamos estos casos de 45 años y más según frecuencia_uso_ia;
- calculamos los porcentajes de frecuencia_uso_ia para los casos de 45 años y más, con un solo decimal.
Encontramos que de las personas de 45 años y más que encuestamos el 41,4% tiene un uso frecuente de la ia.
¿Cómo comparamos grupos?
Muchas veces no queremos describir la base completa, sino comparar grupos.
Por ejemplo, podemos preguntarnos:
¿La frecuencia de uso de IA cambia según el área de trabajo?
Primero podemos contar los casos cruzando dos variables:
encuesta_ia %>%
count(area_trabajo_grupo, frecuencia_uso_ia)# A tibble: 12 × 3
area_trabajo_grupo frecuencia_uso_ia n
<chr> <chr> <int>
1 Consultoría / servicios profesionales esporadicamente 7
2 Consultoría / servicios profesionales frecuente 16
3 Consultoría / servicios profesionales nunca 2
4 Consultoría / servicios profesionales ocasional 14
5 Educación esporadicamente 7
6 Educación frecuente 22
7 Educación nunca 1
8 Educación ocasional 20
9 Salud y servicios sociales esporadicamente 11
10 Salud y servicios sociales frecuente 16
11 Salud y servicios sociales nunca 3
12 Salud y servicios sociales ocasional 20Esta tabla nos muestra cuántas personas hay en cada combinación de área de trabajo y frecuencia de uso de IA. Pero, como los grupos no tienen exactamente la misma cantidad de casos, conviene calcular porcentajes dentro de cada área. Para eso usamos group_by() y mutate().
encuesta_ia %>%
count(area_trabajo_grupo, frecuencia_uso_ia) %>%
group_by(area_trabajo_grupo) %>%
mutate(
porcentaje = round(n / sum(n) * 100, 1)
) %>%
ungroup()# A tibble: 12 × 4
area_trabajo_grupo frecuencia_uso_ia n porcentaje
<chr> <chr> <int> <dbl>
1 Consultoría / servicios profesionales esporadicamente 7 17.9
2 Consultoría / servicios profesionales frecuente 16 41
3 Consultoría / servicios profesionales nunca 2 5.1
4 Consultoría / servicios profesionales ocasional 14 35.9
5 Educación esporadicamente 7 14
6 Educación frecuente 22 44
7 Educación nunca 1 2
8 Educación ocasional 20 40
9 Salud y servicios sociales esporadicamente 11 22
10 Salud y servicios sociales frecuente 16 32
11 Salud y servicios sociales nunca 3 6
12 Salud y servicios sociales ocasional 20 40 Leído paso a paso:
- contamos casos por área de trabajo y frecuencia de uso;
- agrupamos la tabla resultante por área de trabajo;
- calculamos qué porcentaje representa cada frecuencia dentro de cada área;
- desagrupamos, para poder seguir operando.
Esto es importante: el group_by(area_trabajo_grupo) hace que sum(n) se calcule dentro de cada área, no sobre toda la tabla.
Ahora podemos ver que en educación la mayor parte de los casos se concentra entre quienes declaran un uso frecuente u ocasional de IA: 44% y 40%, respectivamente. En consultoría y servicios profesionales también predominan las categorías frecuente y ocasional, aunque con una distribución levemente distinta: 41% declara un uso frecuente y 35,9% un uso ocasional. Pero en salud y servicios sociales, en cambio, el porcentaje de uso frecuente que se observa en la tabla es menor: 32%.
¿Cómo se construye un gráfico con ggplot?
Para hacer gráficos en R, vamos a introducir una herramienta nueva: ggplot2, que se encuentra incluida en tidyverse.
Un gráfico con ggplot se construye por capas. La estructura mínima suele ser esta:
ggplot(datos, aes(x = variable_x, y = variable_y)) +
geom_tipo_de_grafico()Hay tres partes importantes:
| Parte | Qué indica | Ejemplo |
|---|---|---|
datos |
la tabla que vamos a graficar | encuesta_ia |
aes() |
las variables que vamos a ubicar en el gráfico | aes(x = actitud_ia) |
geom_*() |
el tipo de gráfico o capa visual | geom_histogram() |
La palabra aes viene de aesthetics. En ggplot, una estética es una relación entre una variable y un elemento visual del gráfico: eje x, eje y, color, tamaño, forma, etc.
Por ejemplo:
aes(x = frecuencia_uso_ia, y = actitud_media)quiere decir:
poné
frecuencia_uso_iaen el eje x yactitud_mediaen el eje y.
Después agregamos una geometría, es decir, el tipo de elemento visual que queremos usar.
Algunas geometrías frecuentes son:
| Geometría | Para qué sirve |
|---|---|
geom_histogram() |
calcular y dibujar la distribución de una variable numérica |
geom_bar() |
contar casos y dibujar barras |
geom_col() |
dibujar barras con valores ya calculados |
geom_point() |
hacer gráficos de puntos |
geom_line() |
unir puntos con líneas |
geom_text() |
agregar etiquetas de texto |
geom_hline() |
agregar una línea horizontal |
geom_vline() |
agregar una línea vertical |
Un detalle importante: no todas las geometrías esperan los datos de la misma manera.
Algunas geometrías hacen cálculos por nosotros. Por ejemplo, geom_histogram() solo necesita que le indiquemos una variable numérica. Después, R agrupa los valores en intervalos y cuenta cuántos casos hay en cada uno. Algo parecido pasa con geom_bar(): si le damos una variable categórica, cuenta cuántos casos hay en cada categoría y dibuja las barras.
En cambio, geom_col() espera que el cálculo ya esté hecho, de modo que le vamos a pasar una tabla donde una columna indique las categorías y otra columna indique los valores que queremos graficar. Por eso, si ya calculamos una tabla resumen con group_by() y summarise(), seguramente usemos geom_col().
Un detalle importante: ggplot usa + para sumar capas. No es el pipe %>%. El pipe encadena operaciones sobre tablas; el + agrega capas a un gráfico.
Veamos un ejemplo:
glimpse(encuesta_ia)Rows: 139
Columns: 16
$ id_caso <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12…
$ edad <dbl> 45, 57, 45, 60, 55, 30, 65, 68, 59, 1…
$ grupo_edad <chr> "45-59", "45-59", "45-59", "60+", "45…
$ area_trabajo_grupo <chr> "Educación", "Educación", "Educación"…
$ frecuencia_uso_ia <chr> "ocasional", "frecuente", "esporadica…
$ actitud_positiva <dbl> 3, 4, 3, 3, 3, 4, 1, 5, 5, 4, 4, 2, 4…
$ actitud_trabajo_estudio <dbl> 3, 5, 4, 1, 4, 4, 4, 5, 5, 4, 4, 4, 4…
$ actitud_vida_cotidiana <dbl> 4, 5, 4, 1, 4, 5, 4, 5, 5, 4, 5, 4, 4…
$ actitud_aprender_ia <dbl> 4, 4, 4, 3, 3, 4, 4, 5, 5, 3, 3, 3, 4…
$ creencia_decisiones_justas <dbl> 1, 3, 3, 2, 2, 3, 4, 5, 1, 3, 1, 2, 2…
$ creencia_respuestas_certeras <dbl> 2, 2, 3, 3, 2, 4, 5, 5, 2, 4, 4, 2, 1…
$ creencia_orientacion_psicologica <dbl> 1, 2, 1, 2, 1, 3, 4, 3, 1, 1, 2, 2, 2…
$ creencia_compania <dbl> 3, 2, 1, 4, 1, 3, 4, 2, 1, 2, 4, 2, 2…
$ creencia_investigacion <dbl> 4, 3, 3, 1, 4, 4, 2, 5, 2, 4, 2, 2, 2…
$ creencia_ensenanza <dbl> 4, 5, 4, 4, 4, 1, 4, 5, 4, 4, 4, 4, 4…
$ mayor_45 <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, …encuesta_ia %>%
ggplot(aes(x=grupo_edad)) +
geom_bar() +
theme_minimal() # esto es sólo para sacarle fondos y estilos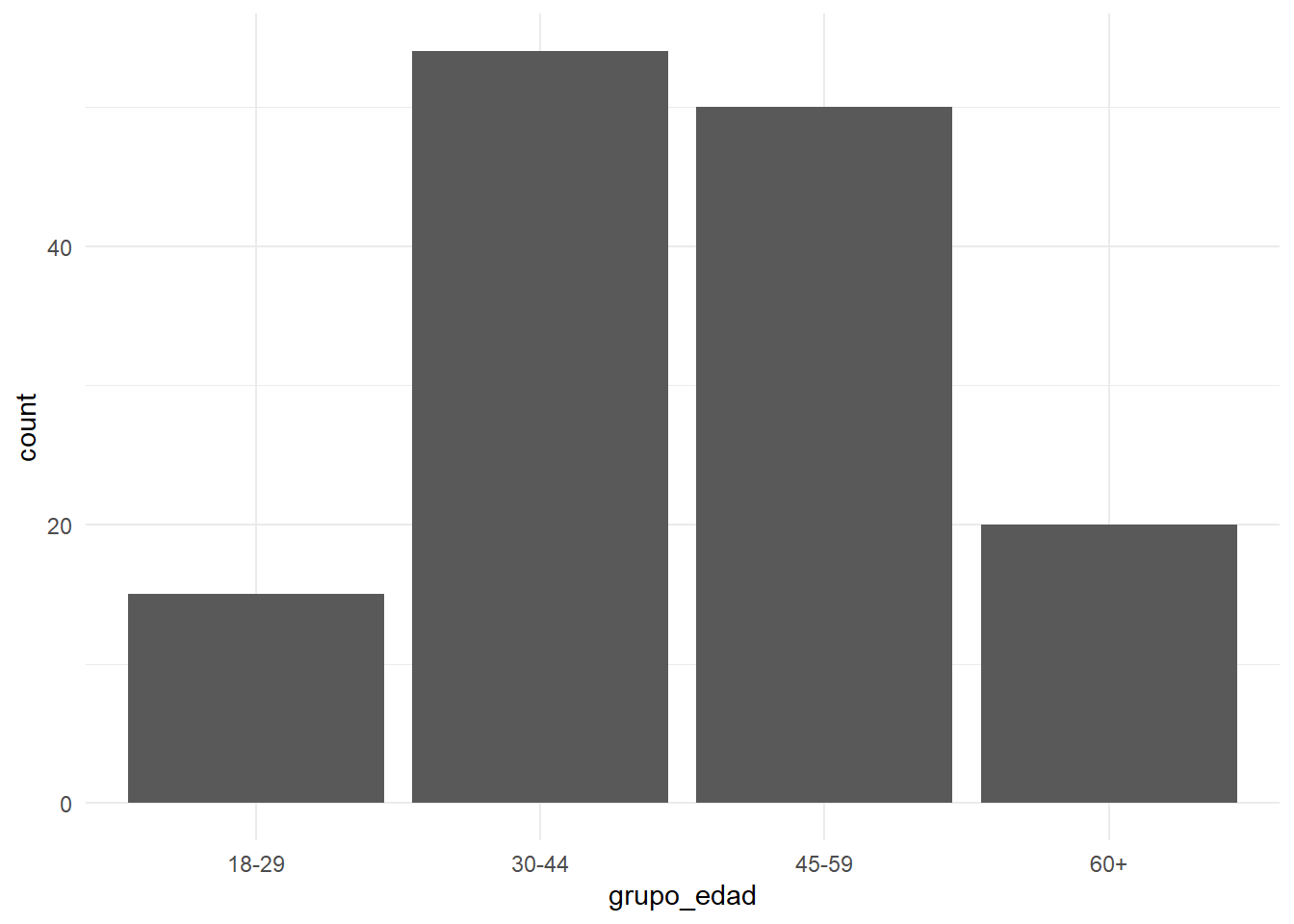
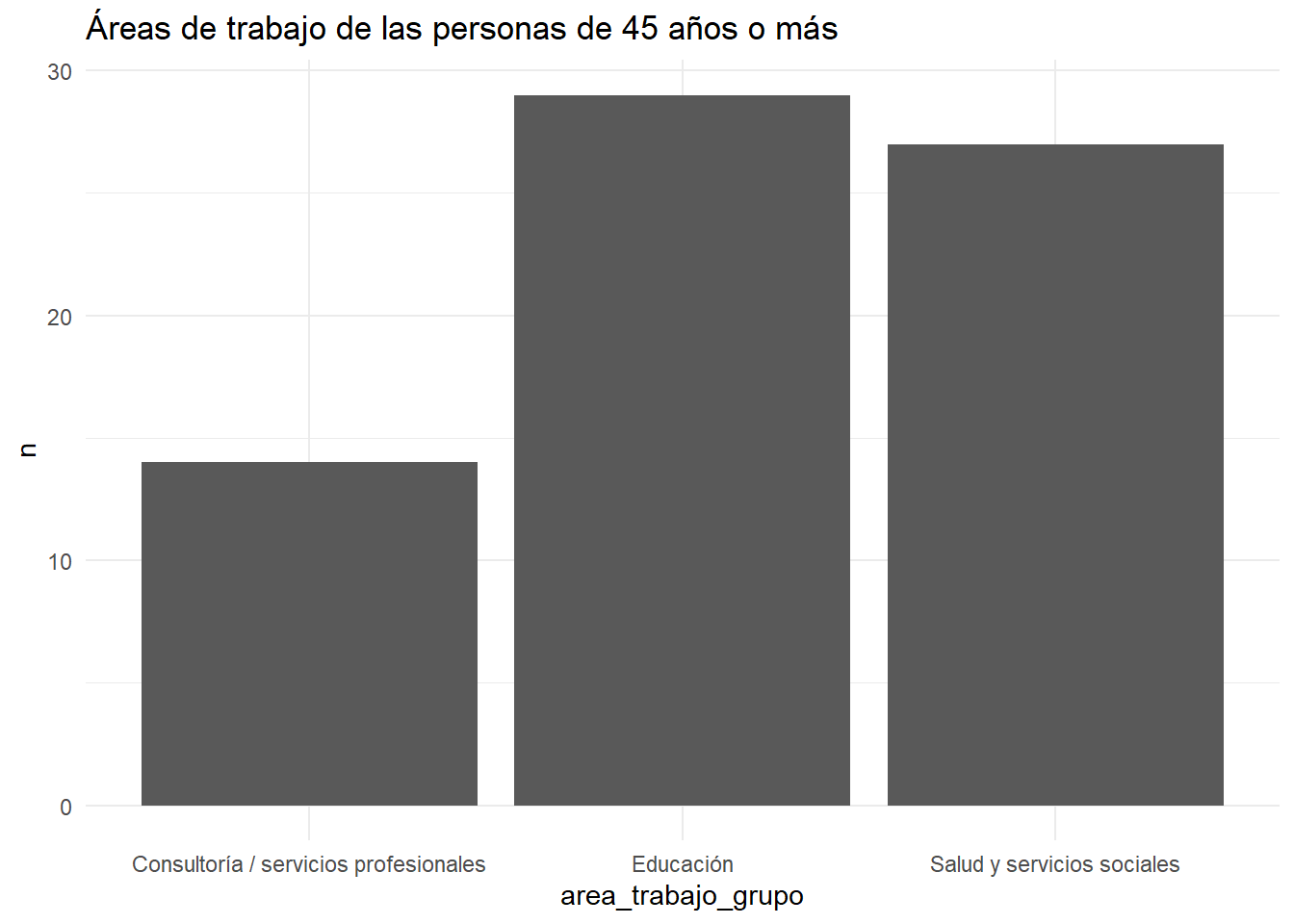
encuesta_ia %>%
filter(mayor_45 == TRUE) %>%
count(area_trabajo_grupo) %>% # al hacer un count generamos una columna n
ggplot(aes(x=area_trabajo_grupo, y=n)) +
geom_col() +
labs( title = "Áreas de trabajo de las personas de 45 años o más" ) + # agregamos un titulo
theme_minimal() # esto es sólo para sacarle fondos y estilos