library(tidyverse)Segundo paso. Exploración de nuestro datasets
Objetivo
En este pasito vamos a empezar a explorar una base de datos en R. Para el final, vas a poder cargar un dataset, reconocer su estructura, identificar sus variables principales y realizar primeras operaciones de inspección.
Trabajaremos con una base de datos construida a partir de una encuesta sobre actitudes, creencias y usos de inteligencia artificial.
¿Cómo cargamos los datos?
Antes de empezar a trabajar, cargamos los paquetes que vamos a usar:
Para cargar los datos vamos a usar la función read_csv(). En R, una función es una instrucción que realiza una tarea específica: recibe cierta información entre paréntesis, la procesa y devuelve un resultado. La función read_csv(), por ejemplo, sirve para leer archivos .csv y viene incluida en el paquete readr, que forma parte del tidyverse.
encuesta_ia <- read_csv(
"https://raw.githubusercontent.com/gastonbecerra/primeros-pasos-r/refs/heads/main/data/encuesta_ia_subset.csv",
show_col_types = FALSE
)(Recordá que podés copiar este código de este tutorial con el botón de portapapeles, y que para correrlo tenés que pegarlo en tu Script y correrlo con Run o Control+Enter)
Con esta línea hacemos tres cosas:
- leemos un archivo
.csvalojado en internet; - lo cargamos en R;
- lo guardamos en un objeto llamado
encuesta_ia.
Podemos ver que el objeto encuesta_ia aparece en el panel Environment. Ese panel nos muestra qué objetos tenemos disponibles durante la sesión de trabajo.
En R, un objeto es un nombre que usamos para guardar información en la memoria de trabajo. En este caso, encuesta_ia es un objeto que contiene una tabla de datos.
Más específicamente, encuesta_ia es un tibble: una versión moderna del data.frame, usada por el tidyverse, que organiza datos en filas y columnas, pero los muestra de forma más ordenada y compacta en la consola.
Si escribimos el nombre del objeto, R nos muestra una vista resumida de la tabla:
encuesta_ia# A tibble: 139 × 15
id_caso edad grupo_edad area_trabajo_grupo frecuencia_uso_ia
<dbl> <dbl> <chr> <chr> <chr>
1 1 45 45-59 Educación ocasional
2 2 57 45-59 Educación frecuente
3 3 45 45-59 Educación esporadicamente
4 4 60 60+ Educación frecuente
5 5 55 45-59 Educación frecuente
6 6 30 30-44 Educación ocasional
7 7 65 60+ Educación ocasional
8 8 68 60+ Educación frecuente
9 9 59 45-59 Educación frecuente
10 10 19 18-29 Educación ocasional
# ℹ 129 more rows
# ℹ 10 more variables: actitud_positiva <dbl>, actitud_trabajo_estudio <dbl>,
# actitud_vida_cotidiana <dbl>, actitud_aprender_ia <dbl>,
# creencia_decisiones_justas <dbl>, creencia_respuestas_certeras <dbl>,
# creencia_orientacion_psicologica <dbl>, creencia_compania <dbl>,
# creencia_investigacion <dbl>, creencia_ensenanza <dbl>En una tabla de datos:
- cada fila representa un caso u observación (una persona encuestada);
- cada columna representa una variable;
- cada celda contiene el valor de una variable para un caso.
¿Cuál es el tamaño de nuestra base?
Para conocer el tamaño de la tabla podemos usar dim().
dim(encuesta_ia)[1] 139 15Esta función devuelve dos números:
- el primero indica la cantidad de filas o casos, en nuestra tabla son 139;
- el segundo indica la cantidad de columnas o variables, que en nuestra tabla son 15.
También podemos consultar cada dimensión por separado con las funciones nrow() y ncol().
nrow(encuesta_ia)[1] 139ncol(encuesta_ia)[1] 15¿Cómo vemos los datos?
Para mirar las primeras filas usamos head().
head(encuesta_ia)# A tibble: 6 × 15
id_caso edad grupo_edad area_trabajo_grupo frecuencia_uso_ia actitud_positiva
<dbl> <dbl> <chr> <chr> <chr> <dbl>
1 1 45 45-59 Educación ocasional 3
2 2 57 45-59 Educación frecuente 4
3 3 45 45-59 Educación esporadicamente 3
4 4 60 60+ Educación frecuente 3
5 5 55 45-59 Educación frecuente 3
6 6 30 30-44 Educación ocasional 4
# ℹ 9 more variables: actitud_trabajo_estudio <dbl>,
# actitud_vida_cotidiana <dbl>, actitud_aprender_ia <dbl>,
# creencia_decisiones_justas <dbl>, creencia_respuestas_certeras <dbl>,
# creencia_orientacion_psicologica <dbl>, creencia_compania <dbl>,
# creencia_investigacion <dbl>, creencia_ensenanza <dbl>Por defecto, head() muestra los primeros registros de la tabla.
Si queremos ver más filas, podemos indicarlo con el argumento n:
head(encuesta_ia, n = 10)# A tibble: 10 × 15
id_caso edad grupo_edad area_trabajo_grupo frecuencia_uso_ia
<dbl> <dbl> <chr> <chr> <chr>
1 1 45 45-59 Educación ocasional
2 2 57 45-59 Educación frecuente
3 3 45 45-59 Educación esporadicamente
4 4 60 60+ Educación frecuente
5 5 55 45-59 Educación frecuente
6 6 30 30-44 Educación ocasional
7 7 65 60+ Educación ocasional
8 8 68 60+ Educación frecuente
9 9 59 45-59 Educación frecuente
10 10 19 18-29 Educación ocasional
# ℹ 10 more variables: actitud_positiva <dbl>, actitud_trabajo_estudio <dbl>,
# actitud_vida_cotidiana <dbl>, actitud_aprender_ia <dbl>,
# creencia_decisiones_justas <dbl>, creencia_respuestas_certeras <dbl>,
# creencia_orientacion_psicologica <dbl>, creencia_compania <dbl>,
# creencia_investigacion <dbl>, creencia_ensenanza <dbl>Esto nos permite hacer una primera inspección rápida:
- ver nombres de columnas;
- mirar valores concretos;
- detectar si la tabla se cargó correctamente;
- reconocer cómo están codificadas algunas variables.
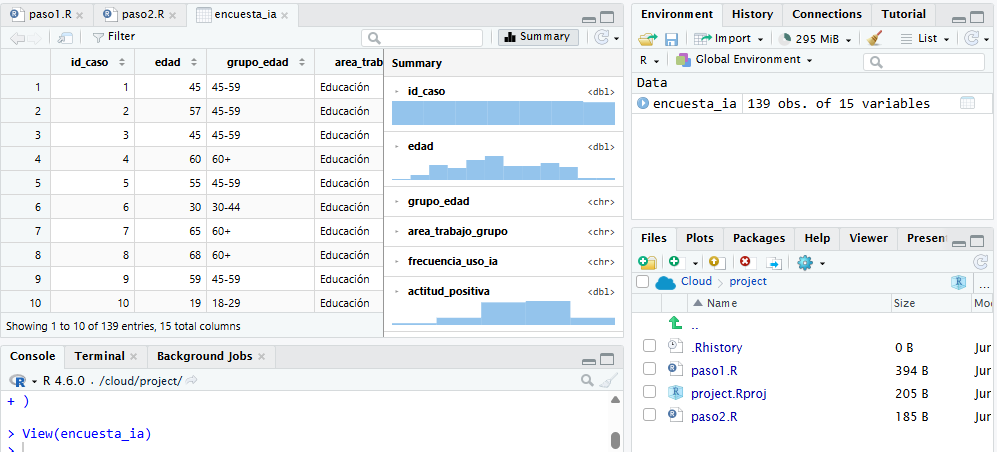
También podemos abrir la tabla en una vista similar a una planilla con View().
View(encuesta_ia)(Importante: R distingue mayúsculas y minúsculas. La función correcta es View() con V mayúscula.)
Esto abre una pestaña en RStudio donde podemos recorrer filas y columnas visualmente. Esto es útil para inspeccionar los datos, pero no reemplaza el código. Mirar la tabla ayuda a orientarnos; escribir código nos permite repetir, documentar y compartir el análisis.
¿Qué tipos de datos tenemos?
glimpse() muestra la estructura de la tabla de una forma compacta.
glimpse(encuesta_ia)Rows: 139
Columns: 15
$ id_caso <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12…
$ edad <dbl> 45, 57, 45, 60, 55, 30, 65, 68, 59, 1…
$ grupo_edad <chr> "45-59", "45-59", "45-59", "60+", "45…
$ area_trabajo_grupo <chr> "Educación", "Educación", "Educación"…
$ frecuencia_uso_ia <chr> "ocasional", "frecuente", "esporadica…
$ actitud_positiva <dbl> 3, 4, 3, 3, 3, 4, 1, 5, 5, 4, 4, 2, 4…
$ actitud_trabajo_estudio <dbl> 3, 5, 4, 1, 4, 4, 4, 5, 5, 4, 4, 4, 4…
$ actitud_vida_cotidiana <dbl> 4, 5, 4, 1, 4, 5, 4, 5, 5, 4, 5, 4, 4…
$ actitud_aprender_ia <dbl> 4, 4, 4, 3, 3, 4, 4, 5, 5, 3, 3, 3, 4…
$ creencia_decisiones_justas <dbl> 1, 3, 3, 2, 2, 3, 4, 5, 1, 3, 1, 2, 2…
$ creencia_respuestas_certeras <dbl> 2, 2, 3, 3, 2, 4, 5, 5, 2, 4, 4, 2, 1…
$ creencia_orientacion_psicologica <dbl> 1, 2, 1, 2, 1, 3, 4, 3, 1, 1, 2, 2, 2…
$ creencia_compania <dbl> 3, 2, 1, 4, 1, 3, 4, 2, 1, 2, 4, 2, 2…
$ creencia_investigacion <dbl> 4, 3, 3, 1, 4, 4, 2, 5, 2, 4, 2, 2, 2…
$ creencia_ensenanza <dbl> 4, 5, 4, 4, 4, 1, 4, 5, 4, 4, 4, 4, 4…Nos informa:
- cuántas filas tiene;
- cuántas columnas tiene;
- el nombre de cada variable;
- el tipo de dato de cada variable;
- algunos valores iniciales.
Así, podemos ver que en este dataset tenemos variables de tres tipos:
| Grupo de variables | Variables |
|---|---|
| Sociodemográficas | edad, grupo_edad, area_trabajo_grupo, frecuencia_uso_ia, generalmente con textos |
| Actitudes | empiezan con actitud_ y tienen valores numéricos entre 1 y 5 |
| Creencias | empiezan con creencia_ y tienen valores numéricos entre 1 y 5 |
¿Qué hay en nuestros datos?
Para tener unas primeras estadísticas de las numéricas, podemos pedir un summary().
summary(encuesta_ia)Con esto podemos empezar a decir algo sobre nuestros datos. Sobre la variable edad podemos decir que la persona más joven tiene 19 años, la mayor tiene 74, y la edad promedio es aproximadamente 45 años. También podemos mirar los ítems de actitud y creencias. Como están medidos en una escala de 1 a 5, sus medias nos dan una primera orientación. En esta salida se observa que algunas variables de actitud tienen promedios relativamente altos, como actitud_vida_cotidiana, mientras que algunas creencias específicas tienen promedios más bajos, como creencia_orientacion_psicologica.
En cambio, para variables guardadas como texto, como grupo_edad, area_trabajo_grupo o frecuencia_uso_ia, summary() no nos da una distribución útil. Para esas variables conviene contar cuántos casos hay en cada categoría. Para eso usamos la función count(), que nos pide como primer argumento que le indiquemos un objeto, y luego que indiquemos qué variable (columna) queremos contar.
count(encuesta_ia, grupo_edad)# A tibble: 4 × 2
grupo_edad n
<chr> <int>
1 18-29 15
2 30-44 54
3 45-59 50
4 60+ 20También podemos contar las áreas de trabaj, o la frecuencia de uso de IA:
count(encuesta_ia, area_trabajo_grupo)# A tibble: 3 × 2
area_trabajo_grupo n
<chr> <int>
1 Consultoría / servicios profesionales 39
2 Educación 50
3 Salud y servicios sociales 50count(encuesta_ia, frecuencia_uso_ia)# A tibble: 4 × 2
frecuencia_uso_ia n
<chr> <int>
1 esporadicamente 25
2 frecuente 54
3 nunca 6
4 ocasional 54Estas tablas son simples, pero ya nos permiten empezar a describir la composición de la base. Por ejemplo, podemos ver si los grupos están equilibrados, si hay categorías con pocos casos, o si alguna respuesta concentra la mayor parte de la muestra. Ah! y también podemos contar dos columnas juntas, para cruzarlas:
count(encuesta_ia, area_trabajo_grupo, frecuencia_uso_ia)# A tibble: 12 × 3
area_trabajo_grupo frecuencia_uso_ia n
<chr> <chr> <int>
1 Consultoría / servicios profesionales esporadicamente 7
2 Consultoría / servicios profesionales frecuente 16
3 Consultoría / servicios profesionales nunca 2
4 Consultoría / servicios profesionales ocasional 14
5 Educación esporadicamente 7
6 Educación frecuente 22
7 Educación nunca 1
8 Educación ocasional 20
9 Salud y servicios sociales esporadicamente 11
10 Salud y servicios sociales frecuente 16
11 Salud y servicios sociales nunca 3
12 Salud y servicios sociales ocasional 20